from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784',version = 1,data_home = ".")X = mnist.data/255
y = mnist.target
# 2019年1月31日訂正
# MNISTのデータセットの変更により、ラベルが数値データになっていないので、
# 以下により、NumPyの配列の数値型に変換します
#mnist数据库变更 label没有变成数值 这里通过numpy来变成数值输出
import numpy as np
y = np.array(y)
y = y.astype(np.int32)import matplotlib.pyplot as plt
%matplotlib inline
plt.imshow(X[0].reshape(28, 28), cmap='gray')
print("この画像データのラベルは{: .0f}です".format(y[0]))この画像データのラベルは 5です
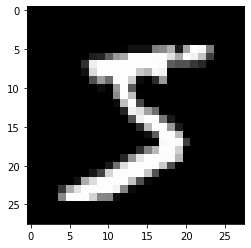
# 制作dataloader
import torch
from torch.utils.data import TensorDataset,DataLoader
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 1/7,random_state = 0)
#将数据转换成pytorch的张量tensor
#在深度学习中,Tensor实际上就是一个多维数组(multidimensional array)其目的是能够创造更高维度的矩阵、向量。
X_train = torch.Tensor(X_train)
X_test = torch.Tensor(X_test)
y_train = torch.LongTensor(y_train)
y_test = torch.LongTensor(y_test)
# 创建一个数据表dataset 包含数据和标签
ds_train = TensorDataset(X_train,y_train)
ds_test = TensorDataset(X_test,y_test)
# BATCH_SIZE:即一次训练所抓取的数据样本数量;
# BATCH_SIZE的大小影响训练速度和模型优化。同时按照以上代码可知,其大小同样影响每一epoch训练模型次数。
# shuffle(中文意思:洗牌,混乱)。shuffle在机器学习与深度学习中代表的意思是,将训练模型的数据集进行打乱的操作。
# 原始的数据,在样本均衡的情况下可能是按照某种顺序进行排列,如前半部分为某一类别的数据,后半部分为另一类别的数据。
# 但经过打乱之后数据的排列就会拥有一定的随机性,在顺序读取的时候下一次得到的样本为任何一类型的数据的可能性相同。
# shuffle 可以防止过拟合
loader_train = DataLoader(ds_train,batch_size = 64,shuffle = True)
loader_test = DataLoader(ds_test,batch_size = 64,shuffle = False)#Keras
from torch import nn
model = nn.Sequential()
# 构建神经网络fc1,fc2,fc3三层
model.add_module('fc1',nn.Linear(28*28*1,100)) #输入784 输出100
model.add_module('relu1',nn.ReLU()) # 输出的100个 通过ReLU转换 负数转换为0 正数原值输出
model.add_module('fc2',nn.Linear(100,100))
model.add_module('relu2',nn.ReLU())
model.add_module('fc3',nn.Linear(100,10)) # 输出标签0-9 共十个分支
print(model)
Sequential(
(fc1): Linear(in_features=784, out_features=100, bias=True)
(relu1): ReLU()
(fc2): Linear(in_features=100, out_features=100, bias=True)
(relu2): ReLU()
(fc3): Linear(in_features=100, out_features=10, bias=True)
)
# 误差函数和最优化
from torch import optim
# 误差函数设定
loss_fn = nn.CrossEntropyLoss()
# 权重学习的最优化选择
optimizer = optim.Adam(model.parameters(),lr = 0.01)adams 算法
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
它的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。其公式如下:
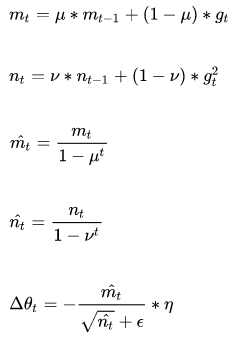
其中,前两个公式分别是对梯度的一阶矩估计和二阶矩估计,可以看作是对期望E|gt|,E|gt^2|的估计;
公式3,4是对一阶二阶矩估计的校正,这样可以近似为对期望的无偏估计。可以看出,直接对梯度的矩估计对内存没有额外的要求,而且可以根据梯度进行动态调整。最后一项前面部分是对学习率n形成的一个动态约束,而且有明确的范围。
params(iterable):可用于迭代优化的参数或者定义参数组的dicts。
lr (float, optional) :学习率(默认: 1e-3)
betas (Tuple[float, float], optional):用于计算梯度的平均和平方的系数(默认: (0.9, 0.999))
eps (float, optional):为了提高数值稳定性而添加到分母的一个项(默认: 1e-8)
weight_decay (float, optional):权重衰减(如L2惩罚)(默认: 0)
def train(epoch):
model.train()
for data,targets in loader_train:
optimizer.zero_grad() #计算后归零
outputs = model(data) # 输入data 求输出
loss = loss_fn(outputs,targets) # 计算输出和训练数据正确值的误差
loss.backward()
optimizer.step()
print("epoch{}:终止\n".format(epoch))
def test():
model.eval() #推理模式
correct = 0
with torch.no_grad(): #?推导不需要微分?
for data ,targets in loader_test:
outputs = model(data)
_,predicted = torch.max(outputs.data,1) #计算概率最高的标签
#torch.max(a, 0): 返回每一列的最大值,且返回索引(返回最大元素在各列的行索引)。
#torch.max(a, 1): 返回每一行的最大值,且返回索引(返回最大元素在各行的列索引)。
# 注意运算符的全角半角
correct += predicted.eq(targets.data.view_as(predicted)).sum() #如果和正确值一致,计数加一
data_num = len(loader_test.dataset) #数据的总数
print('\n 实验数据的正确率:{}/{} ({: .0f}%) \n'.format(correct,data_num,100. *correct/data_num))test() # 初始不学习进行推导
# 这个时候的准确率和随机选择的概率接近
实验数据的正确率:1142/10000 ( 11%)
for epoch in range(3):
train(epoch)
test()epoch0:终止
epoch1:终止
epoch2:终止
实验数据的正确率:9565/10000 ( 96%)
index = 2018
model.eval()
data = X_test[index]
output = model(data)
_,predicted = torch.max(output.data,0)
print("预测结果是{}".format(predicted))
X_test_show = (X_test[index]).numpy()
plt.imshow(X_test_show.reshape(28,28),cmap = 'gray')
print("这个画像数据的正确标签是{: .0f}".format(y_test[index]))预测结果是2
这个画像数据的正确标签是 2
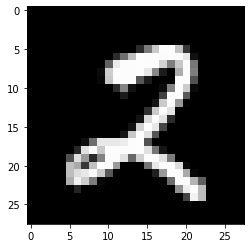
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self,n_in,n_mid,n_out):
super(Net,self).__init__()
self.fc1 = nn.Linear(n_in,n_mid)
self.fc2 = nn.Linear(n_mid,n_mid)
self.fc3 = nn.Linear(n_mid,n_out)
def forward(self,x):
h1 = F.relu(self.fc1(x))
h2 = F.relu(self.fc2(h1))
output = self.fc3(h2)
return output
model = Net(n_in = 28*28*1,n_mid = 100,n_out = 10)
print(model)Net(
(fc1): Linear(in_features=784, out_features=100, bias=True)
(fc2): Linear(in_features=100, out_features=100, bias=True)
(fc3): Linear(in_features=100, out_features=10, bias=True)
)



