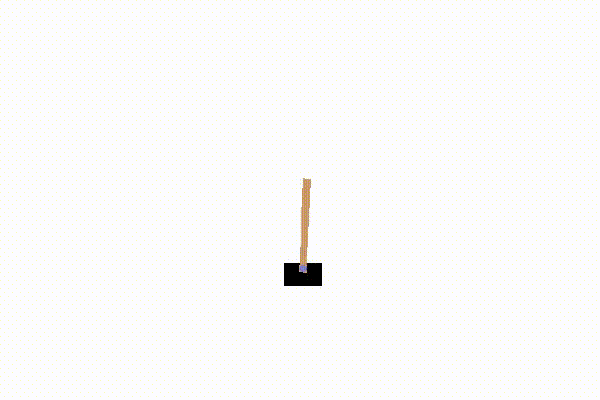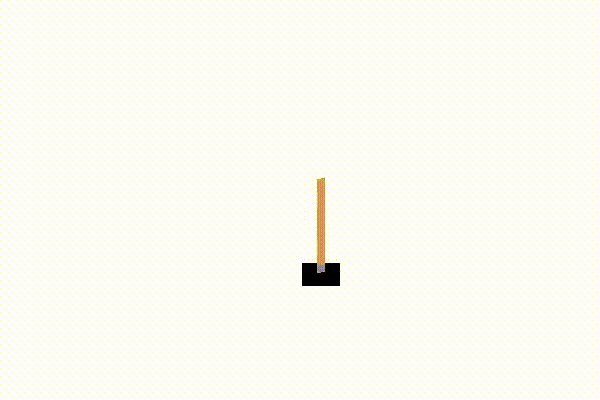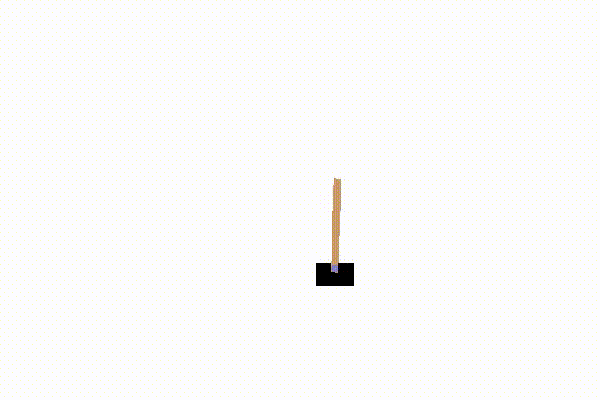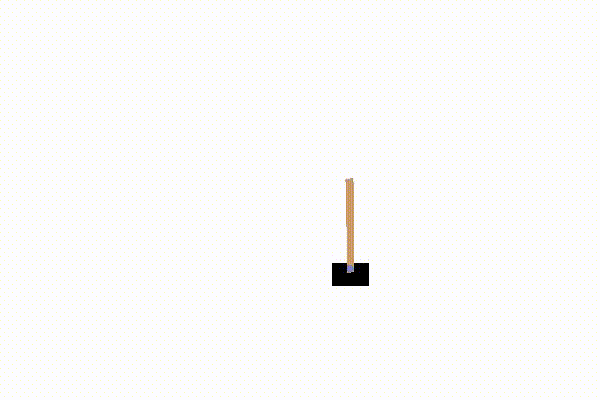这里的模型是gym库的cartpole-v0
采用深入学习Q学习
构建agent,brain,environment
对于研究的模型来说可以通过gym来自己创建模型,具体操作之后学习
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import gymfrom JSAnimation.IPython_display import display_animation
from matplotlib import animation
from IPython.display import display
# jupyter notebook gif动画保存方法
def display_frames_as_gif(frames):
plt.figure(figsize=(frames[0].shape[1]/72.0, frames[0].shape[0]/72.0),
dpi=72)
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames),
interval=50)
anim.save('movie_cartpole.mp4') # 追記:動画の保存です
display(display_animation(anim, default_mode='loop'))ENV = 'CartPole-v0'
NUM_DIZITIZED = 6
GAMMA = 0.99
ETA = 0.5
MAX_STEPS = 200
NUM_EPISODES = 1000
class Agent:
def __init__(self,num_states,num_actions):
self.brain = Brain(num_states,num_actions) #生成决定agent动作的brain
# Q函数更新
def update_Q_function(self,observation,action,reward,observation_next):
self.brain.update_Q_table(observation,action,reward,observation_next)
def get_action(self,observation,step):
action = self.brain.decide_action(observation,step)
return action
class Brain:
def __init__(self,num_states,num_actions):
self.num_actions = num_actions # 决定单摆的行动 两个选择(left,right)
self.q_table = np.random.uniform(low = 0,high = 1,size = (NUM_DIZITIZED**num_states,num_actions))
# 制作Qtable 行数是离散化后状态4个变量的数值 列数是行动执行数 num_states :4 num_actions:2
def bins(self,clip_min,clip_max,num):
# 记得写self 。。。全是泪
return np.linspace(clip_min,clip_max,num+1)[1:-1]
# 这里的np.linspace是去生成等间隔数列
# 对于index来说通常[-1]指的是最后一个元素
#[-1:1]指的是第二个元素到最后一个元素的前一个元素
#numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None).在指定的间隔内返回均匀间隔的数字。返回num均匀分布的样本,在[start, stop]。
def digitize_state(self,observation):
# 这里起初错erro为 digitize_state() takes 1 positional argument but 2 were given
# 函数定义的时候忘记写self 只有observation一个参数所以显示错误 因为之后赋予了两个变量
cart_pos,cart_v,pole_angle,pole_v = observation
digitized = [
np.digitize(cart_pos,bins = self.bins(-2.4,2.4,NUM_DIZITIZED)),
np.digitize(cart_v,bins = self.bins(-3.0,3.0,NUM_DIZITIZED)),
np.digitize(pole_angle,bins = self.bins(-0.5,0.5,NUM_DIZITIZED)), ##pole_angle是rad单位
np.digitize(pole_v,bins = self.bins(-2.0,2.0,NUM_DIZITIZED)),
]
#被赋予了两个形参 因为= 后方写成bins而不是self.bins
return sum([x*(NUM_DIZITIZED**i) for i,x in enumerate(digitized)])
# 通过enumerate()遍历列表获得一个索引序列,同时获得索引和值。这里返回值是状态函数的离散化后的表现形式
# 假设离散化后的列表为[1,2,3,4] 则状态 = 1*1 +2*6+3*36+4*216 = 985
def update_Q_table(self, observation, action, reward, observation_next):
'''QテーブルをQ学習により更新'''
state = self.digitize_state(observation) # 状態を離散化
state_next = self.digitize_state(observation_next) # 次の状態を離散化
Max_Q_next = max(self.q_table[state_next][:])
self.q_table[state, action] = self.q_table[state, action] + ETA * (reward + GAMMA * Max_Q_next - self.q_table[state, action])
def decide_action(self,observation,episode):
state = self.digitize_state(observation)
epsilon = 0.5 * (1/(episode + 1)) # epsilon 概率下随机执行行动 1-epsilon的概率下执行Q价值最大行动 概率随时间变化
if epsilon <= np.random.uniform(0,1):
action = np.argmax(self.q_table[state][:])
else:
action = np.random.choice(self.num_actions)
return actionclass Environment :
def __init__(self):
self.env = gym.make(ENV) #将模型环境设定
num_states = self.env.observation_space.shape[0] #获取状态变量种类数量4
num_actions = self.env.action_space.n # 获取行动执行种类数量2
self.agent = Agent(num_states,num_actions)
def run(self):
complete_episodes = 0
is_episode_final = False
frames = []
for episode in range(NUM_EPISODES):
observation = self.env.reset() #环境的初始化
for step in range(MAX_STEPS):
if is_episode_final is True: #当此次试行是最终试行的话 就将各个时刻的画像追加到frames里面
frames.append(self.env.render(mode = 'rgb_array'))
action = self.agent.get_action(observation,episode) # 行动计算
observation_next, _ ,done, _ = self.env.step(action) # reward 和 info不使用 这里用 _
if done: # 这里的done代表当前试行结束 结束条件为 step超过200 或者模型超过一定角度
if step < 195: # 195step内如果倒了则reward给与-1
reward = -1
complete_episodes = 0 # 未成功则归0
else:
reward = 1
complete_episodes +=1 #记录更新
else:
reward = 0 #试行中途的reward为0
self.agent.update_Q_function(observation,action,reward,observation_next)
# 这里注意缩进 因为这里Q更新是在for step in range(MAX_STEPS)条件下的操作
#step+1的状态下 通过observation_next来更新Q函数
observation = observation_next
if done: #试行结束 是否和之前的条件语句调换位置 依然不影响结果?
print('{0} Episode: Finish after {1} time steps'.format(episode,step + 1))
break
if is_episode_final is True:
display_frames_as_gif(frames)
break
if complete_episodes >= 10:
print('10回連続成功')
is_episode_final = Truecartpole_env = Environment()
cartpole_env.run()
0 Episode: Finish after 28 time steps
1 Episode: Finish after 10 time steps
2 Episode: Finish after 21 time steps
3 Episode: Finish after 26 time steps
4 Episode: Finish after 16 time steps
5 Episode: Finish after 12 time steps
6 Episode: Finish after 26 time steps
7 Episode: Finish after 9 time steps
8 Episode: Finish after 16 time steps
9 Episode: Finish after 17 time steps
10 Episode: Finish after 25 time steps
11 Episode: Finish after 12 time steps
12 Episode: Finish after 9 time steps
13 Episode: Finish after 43 time steps
14 Episode: Finish after 15 time steps
15 Episode: Finish after 12 time steps
16 Episode: Finish after 9 time steps
17 Episode: Finish after 74 time steps
18 Episode: Finish after 48 time steps
19 Episode: Finish after 22 time steps
20 Episode: Finish after 32 time steps
.
.
.
140 Episode: Finish after 37 time steps
141 Episode: Finish after 200 time steps
142 Episode: Finish after 200 time steps
143 Episode: Finish after 185 time steps
144 Episode: Finish after 185 time steps
145 Episode: Finish after 162 time steps
.
.
.
241 Episode: Finish after 200 time steps
242 Episode: Finish after 140 time steps
243 Episode: Finish after 200 time steps
244 Episode: Finish after 200 time steps
245 Episode: Finish after 200 time steps
246 Episode: Finish after 200 time steps
247 Episode: Finish after 146 time steps
248 Episode: Finish after 186 time steps
249 Episode: Finish after 200 time steps
250 Episode: Finish after 179 time steps
251 Episode: Finish after 127 time steps
252 Episode: Finish after 112 time steps
253 Episode: Finish after 105 time steps
254 Episode: Finish after 200 time steps
255 Episode: Finish after 200 time steps
256 Episode: Finish after 200 time steps
257 Episode: Finish after 110 time steps
258 Episode: Finish after 85 time steps
259 Episode: Finish after 31 time steps
260 Episode: Finish after 91 time steps
261 Episode: Finish after 200 time steps
262 Episode: Finish after 200 time steps
263 Episode: Finish after 200 time steps
264 Episode: Finish after 131 time steps
265 Episode: Finish after 180 time steps
266 Episode: Finish after 139 time steps
267 Episode: Finish after 99 time steps
268 Episode: Finish after 135 time steps
269 Episode: Finish after 129 time steps
270 Episode: Finish after 184 time steps
271 Episode: Finish after 123 time steps
272 Episode: Finish after 78 time steps
273 Episode: Finish after 174 time steps
274 Episode: Finish after 169 time steps
275 Episode: Finish after 140 time steps
276 Episode: Finish after 200 time steps
277 Episode: Finish after 111 time steps
278 Episode: Finish after 125 time steps
279 Episode: Finish after 96 time steps
280 Episode: Finish after 200 time steps
281 Episode: Finish after 185 time steps
282 Episode: Finish after 97 time steps
283 Episode: Finish after 200 time steps
284 Episode: Finish after 184 time steps
285 Episode: Finish after 143 time steps
286 Episode: Finish after 200 time steps
287 Episode: Finish after 200 time steps
.
.
.
393 Episode: Finish after 200 time steps
394 Episode: Finish after 196 time steps
395 Episode: Finish after 200 time steps
396 Episode: Finish after 200 time steps
397 Episode: Finish after 200 time steps
398 Episode: Finish after 200 time steps
399 Episode: Finish after 200 time steps
400 Episode: Finish after 200 time steps
401 Episode: Finish after 200 time steps
402 Episode: Finish after 200 time steps
10回連続成功
403 Episode: Finish after 200 time steps